以長三角某智算中心為例 揭秘多智算中心一體化運營運維與結算體系
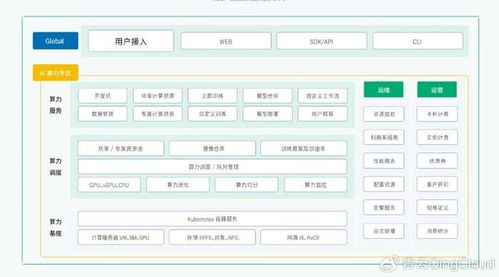
隨著人工智能產業的爆發式增長,多地、多中心的智能計算中心(智算中心)已成為支撐區域乃至國家算力網絡的關鍵基礎設施。其高效、穩定、經濟的運營運維(O&M)與精準的設備結算體系,是實現算力資源高效調度與商業價值最大化的核心。本文將以長三角地區某大型運營商主導的“一核多翼”智算中心集群為例,系統闡述其運營運維與結算體系的構建與實踐。
一、 案例背景:一體化“算力網”的構建
該案例中的智算中心集群,以位于上海的核心樞紐數據中心為“核心”,在杭州、南京、蘇州等地建設了多個具有差異化算力配置(如側重AI訓練、推理或科學計算)的邊緣智算節點為“多翼”。目標是通過統一平臺,實現跨地域算力資源的整合、彈性調度與一體化服務。
二、 核心挑戰與運營運維架構
面對地理分散、技術棧復雜、需求多樣等挑戰,該集群構建了“集中管控+屬地執行”的混合運營運維模式。
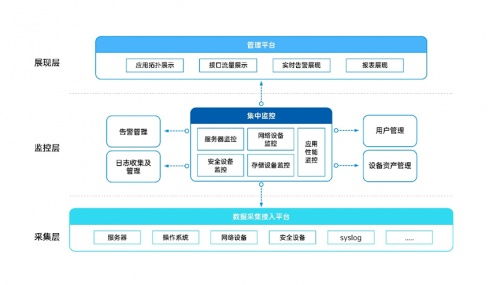
- 集中運營中心(COC):設立于上海核心樞紐,承擔“大腦”職能。
- 統一監控:通過自研的運維管理平臺,對全部中心的IT設備(GPU服務器、存儲、網絡)、動力環境(電力、制冷)進行7x24小時實時全景監控。
- 資源調度與編排:根據客戶作業需求、各中心資源利用率、網絡延遲和電價等因素,通過智能算法實現算力任務的跨中心最優部署。
- 標準化流程制定:建立統一的設備上架、巡檢、變更、故障處理(SOP)和應急預案。
- 屬地運維團隊:各智算中心駐地配備專職技術團隊,負責:
- 現場物理操作:硬件巡檢、設備上下架、線纜維護、本地故障初步排查與硬件更換。
- 執行標準化流程:嚴格遵循COC下發的工單和指令進行現場操作。
- 協同支持:與當地電力、網絡供應商對接,保障基礎設施穩定。
- 智能化運維(AIOps)應用:平臺利用AI進行故障預測(如通過GPU運行日志預測顯存故障)、能耗優化(動態調整制冷策略)和容量規劃,變被動響應為主動預防。
三、 關鍵環節:精細化設備結算體系
清晰的結算體系是商業運營的基石,尤其涉及高價值的GPU等算力設備。該案例采用“資源度量 + 服務分級 + 動態計價”的模型。
- 結算對象與度量維度:
- 算力資源:以“GPU卡時”或“算力單元(如FP16 TFLOPS-小時)”為核心度量單位,精確記錄客戶占用的各類GPU(如A100、H800)的計算時長。
- 存儲資源:按高速SSD存儲的容量(GB)和I/O吞吐量分級計費。
- 網絡資源:跨中心數據遷移流量、對外帶寬單獨計量。
- 軟件與服務:預置的AI框架、模型庫及專業調優服務按許可或服務包形式結算。
- 結算流程與平臺:
- 統一賬戶與計量:客戶擁有唯一賬戶,可在平臺上跨中心申請和使用資源。底層計量系統自動采集所有資源消耗數據,匯聚至結算中心。
- 賬單生成:根據預設的價目表(單價可能因數據中心區位、采購成本、實時負載產生浮動),按日或按周生成明細賬單,清晰展示各中心、各項目的消耗量與費用。
- 差異化定價策略:
- 地域差價:考慮當地電費、建設成本,不同中心的算力單價略有差異。
- 承諾用量折扣:客戶承諾長期使用一定量算力,可獲得階梯價格優惠。
- 競價模式:對于非實時性任務,可提交至“算力資源池”,以競價方式使用空閑算力,成本顯著降低。
- 設備資產與成本分攤:對于自購或租賃的GPU服務器等硬件設備,其折舊/租金、運維成本(電力、制冷、人工)被科學地分攤到每個“算力單元”中,作為定價的基礎成本,確保財務模型的可持續性。
四、 成效與啟示
通過上述體系,該智算中心集群實現了:
- 運營效率提升:故障平均修復時間(MTTR)降低30%,資源整體利用率提升至65%以上。
- 客戶體驗優化:客戶可“一點接入,全網算力”,按需取用,賬單透明。
- 商業閉環清晰:形成了從資源供給、監控調度、計量計費到財務回款的完整閉環。
結論
多地智算中心的運營運維絕非單個數據中心的簡單復制。它要求構建一個技術驅動、流程統一、財務透明的整體系統。成功的核心在于通過集中化的智能平臺實現“管控合一”,并通過精細化的結算模型將分散的物理設備轉化為可靈活銷售、收益明確的算力服務,從而真正釋放規模化的算力網絡價值。本案例為同類項目的規劃與運營提供了可借鑒的實踐框架。
如若轉載,請注明出處:http://m.dqccb.com.cn/product/22.html
更新時間:2026-05-24 14:35:22